Serverless with Rust and Protocol Buffers
I’ve recently been working on rewriting our small service with Rust for fun. One reason is to see if Rust, as a system programming language, is ready for cloud development in 2023. Another reason is that I wonder how much better it is compared to Python or Java in major cloud and data computing.
💡 There is a lot of discussion over which language to use as a serverless service. In my point of view, dynamic languages like Python lack compile-time checks, which can cause more runtime errors than static languages like Rust or Java.
Another reason is that Python and Java need a runtime process (JVM, CPython) to run your actual code, which means they can’t run natively like compiled Rust does. However, I’m not sure about the performance gap. Furthermore, Rust doesn’t require garbage collection, so ideally, a program’s heap size should fluctuate less than a garbage-collected language when running. That means Lambda or Function underlying infrastructure controller should be able to handle invocation or scaling more easily.
In terms of language paradigms, in my opinion, compared to traditional OOP, the modern ML (meta-language) family has a better design for scalable cloud services.
1 Working Protobuf with Prost
Here’s a diagram showing the simplified architecture of one of our Lambda services.

In order to do that, I have to research Rust libraries that bring additional functionality to existing services, such as asynchronous ecosystems, Protocol Buffers, and cloud SDKs. Luckily, I found that the Rust community has been quite serious about porting Rust to the cloud, especially for AWS. Some examples include:
- AWS Rust SDK (although it’s still in the preview stage)
- Cargo Lambda (which even uses Zig for cross compiling linker )
- Prost (Protocol Buffers implementation for Rust)
- aws-lambda-rust-runtime (For you to run Rust application on Lambda)
- Mountpoint S3 (mounting S3 bucket as a local file system)
These crates provide a great development experience when writing cloud services. However, after trying some of them, I found that there are still some features that need to be added or other inconvenient parts. For example, Prost is heavily based on tonic. So if you only want to use Prost without tonic, you may want to use a tool like proto-gen (made by Embark Studios) , which provides a feature-rich CLI over Prost.
💡 To understand how Protocol Buffers (protobuf) works under the hood, I recommend reading this article: Protobufs Explained. In essence Protocol Buffers, aka… | by Giga Gatenashvili
Let’s look at our makefile for generating Rust code using *.proto
|
|
Prost also support Protobuf well-known types . But it come with a seperate crate.
|
|
Once Rust structs been generated, we can use them to decode the corresponding schema like this:
|
|
💡 However, I have not yet tried it with a length-delimited
.protofile. I will update here once I get it to work.
2 SDK for AWS Lambda
Once we can handle the Protobuf file, we can start porting to the cloud and test the data digest flow. Here, we use Tokio and the AWS Rust SDK to build our small consumer service. You can see that we use the crate AWS_Lambda_Events
to help us use our SqsEvent more easily.
|
|
Once we receive an SQS event that records a Protobuf file located in an S3 bucket, we can start consuming them.
|
|
Finally, decode it into JSON format and send it to the landing bucket.
|
|
3 Evaluation
Once we have completed our Lambda code and tested it successfully using LocalStack, we will deploy it to our cloud. Thanks to Cargo Lambda, the deployment experience has been really smooth.
💡 Since Lambda does not officially support the Rust runtime yet, we need to use a custom runtime on AWS Linux 2. Fortunately, there is already a pre-built runtime for Rust published by AWS, which can be found at here .
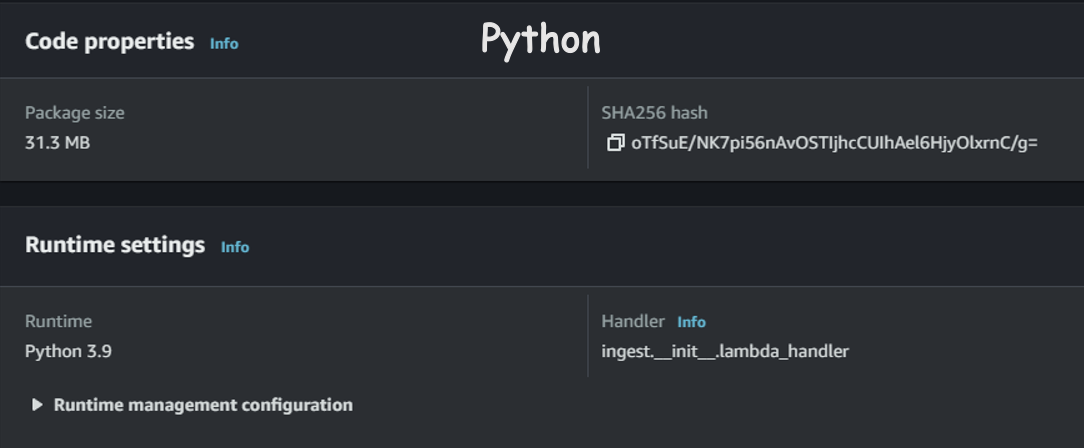
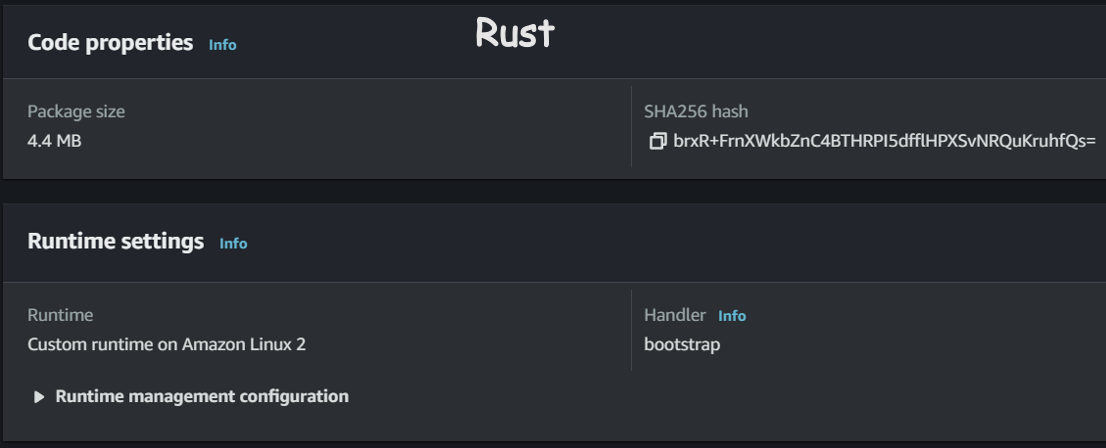
3.1 Package Size
Here, we compared our Rust application to the Python application, and the size is about 7 times smaller in Rust.
💡 Disclaimer: The Lambda function has not fully implemented all of our existing functions, and the testing scenario is not rigorous.
3.2 Performance
The performance difference between the Rust and Python applications is about 8 times faster, although there are some duration spikes in Rust. I think this might be due to the Rust runtime not yet being stable in the Lambda environment. However, this is just a rough test, and no serious stress test has been applied.


4 Take Away
After experimenting with Rust on AWS Lambda, I found the development experience to be quite impressive. Since most of our cloud applications are I/O-bound, async plays a significant role in implementing a well-performing service. As the Rust ecosystem continues to mature and adopt async (although we still need the async trait macro for now), the possibility of Rust cloud applications becomes more feasible. However, this demo is just a simple function that performs a basic task. If Rust wants to be widely adopted for data streaming or backend deployment, it needs more SDK support. Currently, I have only seen AWS attempt to make Rust a viable option on their end, and it is still in the preview stage. Therefore, there is still a long way to go.
5 TODO
After failing with Prost decode with length-delimited proto file, I will try to debug it after we upgrade our schema from proto2 to proto3 and see if there is a bug inside our schema or if it’s a file format error. (Since Python can successfully decode, I think there might be a bug inside the Prost crate, but I’m not sure.)
